El archivo robots.txt es una herramienta esencial para controlar cómo los motores de búsqueda acceden a tu web. Permite impedir que ciertas partes de la web sean rastreadas o indexadas, evitando que contenido sensible, duplicado o irrelevante aparezca en los resultados de búsqueda.
En esta guía aprenderás todo lo necesario para configurar robots.txt de manera segura y efectiva, incluyendo ejemplos prácticos, errores frecuentes y cómo indicar la ubicación de tu sitemap para acelerar la indexación de las páginas importantes de tu web.
1. ¿Qué es y para qué sirve robots.txt?
El archivo robots.txt es un archivo de texto ubicado en el directorio raíz de tu web y que permite controlar cómo los motores de búsqueda rastrean su contenido. Su función principal es indicar a los robots qué secciones de la web pueden o no pueden explorar, evitando que contenido sensible o irrelevante aparezca en los resultados de búsqueda.
Este archivo es especialmente útil para proteger carpetas privadas, páginas de administración o contenido temporal que no deseas indexar en Google. Al configurarlo correctamente, puedes mejorar la eficiencia del rastreo, asegurarte de que las páginas importantes sean priorizadas y evitar problemas de duplicidad de contenido.
2. Ejemplo básico de configuración de robots.txt
Supongamos que quieres evitar que Google y otros buscadores accedan a los archivos de administración de tu web. Para ello, debes crear o editar el archivo robots.txt de la siguiente manera:
User-agent: * Disallow: /admin
Esto significa que: todos los robots (User-agent: *) no pueden entrar en la carpeta /admin.
Ten cuidado: si escribes Disallow: / sin indicar una ruta concreta, ya que estarías bloqueando toda tu web, y Google no podría rastrear ninguna página.
Para comprobar que tu robots.txt funciona correctamente, tienes dos opciones fáciles:
- Acceder directamente al archivo robots.txt.
Escribe en tu navegadorwww.tudominio.com/robots.txty revisa su contenido. - Usar la herramienta de Google.
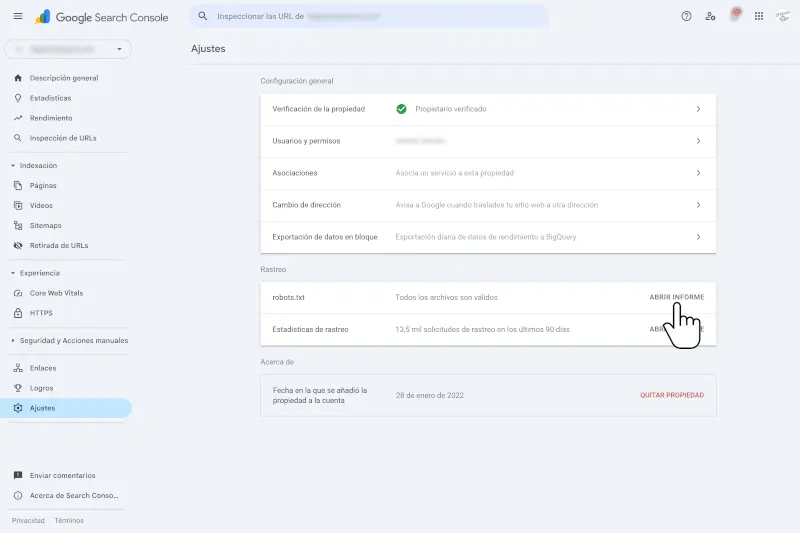
Ve a Search Console > Rastreo > robots.txt y verifica que no haya errores.
3. Usar robots.txt para indicar la ubicación del sitemap
Además de bloquear rutas, el archivo robots.txt se puede usar para indicar a los motores de búsqueda dónde se encuentra tu sitemap. Esto ayuda a que los buscadores descubran todas tus páginas de manera más rápida y eficiente.
User-agent: * Sitemap: http://www.tudominio.com/sitemap.xml
Al incluir la ubicación del sitemap, Google y otros buscadores pueden rastrear e indexar tus páginas importantes más fácilmente, evitando que URLs relevantes se pierdan y acelerando la aparición de contenido nuevo en los resultados de búsqueda.
Recuerda que el sitemap debe estar actualizado y completo, incluyendo todas las páginas que quieres que Google indexe, para maximizar la eficiencia del rastreo y mejorar el SEO de tu web.
4. Meta etiqueta robots: controlar la indexación de páginas individuales
Además del archivo robots.txt, puedes controlar la indexación de páginas específicas mediante la meta etiqueta robots. Esta etiqueta se coloca dentro de la sección <head> de cada página de tu web y permite indicar a los buscadores cómo tratar esa página concreta.
Los atributos más comunes son:
- noindex.
Indica que la página no debe aparecer en los resultados de búsqueda. - nofollow.
Indica que los enlaces de esa página no deben ser seguidos por los motores de búsqueda.
Ejemplo de uso dentro del <head> de una página:
<meta name="robots" content="noindex, nofollow">
Esta etiqueta es especialmente útil para páginas concretas que no quieres indexar, como páginas de login, formularios internos, resultados de búsqueda internos de tu web o contenido duplicado, incluso si están accesibles para los bots.
Combinada con robots.txt, te permite tener un control completo sobre qué el lo que se rastrea e indexa en tu web, mejorando la eficiencia del rastreo y evitando que el contenido irrelevante aparezca en Google.
5. Resumen y recomendaciones
Después de aprender cómo funciona robots.txt y la meta etiqueta robots, es importante repasar las mejores prácticas para asegurar que tu web se rastrea e indexa correctamente.
Aplicando estas recomendaciones, puedes proteger contenido sensible, mejorar la eficiencia del rastreo y asegurarte de que Google muestra solo tus páginas más relevantes.
- Usa robots.txt.
Para bloquear carpetas o páginas completas que no quieres que Google rastree. - Indica la ubicación del sitemap.
En robots.txt para facilitar que los motores de búsqueda encuentren e indexen todas tus páginas importantes. - Revisa siempre.
Que no bloquees por error secciones relevantes de tu web, evitando problemas de rastreo e indexación. - Usa la meta etiqueta robots.
En páginas individuales que no quieres indexar o cuyos enlaces no quieres que se sigan, como páginas de login, formularios internos o contenido duplicado.
Controlar correctamente el rastreo e indexación de tu web es fundamental para asegurarte de que Google ve y muestra únicamente el contenido relevante.
Esto evitará problemas de visibilidad en los resultados de búsqueda y mejora el SEO general de tu sitio, aumentando la probabilidad de que tus páginas importantes aparezcan en los primeros puestos.
¿Te ha resultado útil este artículo? Compártelo